


|
SADA Main Page
Free Downloads
Visualization
Sampling
Data Exploration
Risk Assessment
Geospatial Analysis
Geospatial Simulation
Decision Analysis
Cost Benefit Anaylsis
MARSSIM
TRIAD
Other Tools
Technical Support
Documentation
Coming Soon
Training
Education
Applications
Join SADA User Group
RAIS
Bugs
People
Email Us
Current SADA Webpage Vistors 
Previous SADA Webpage Visitors  |
Spatial Analysis and Decision Assistance
|
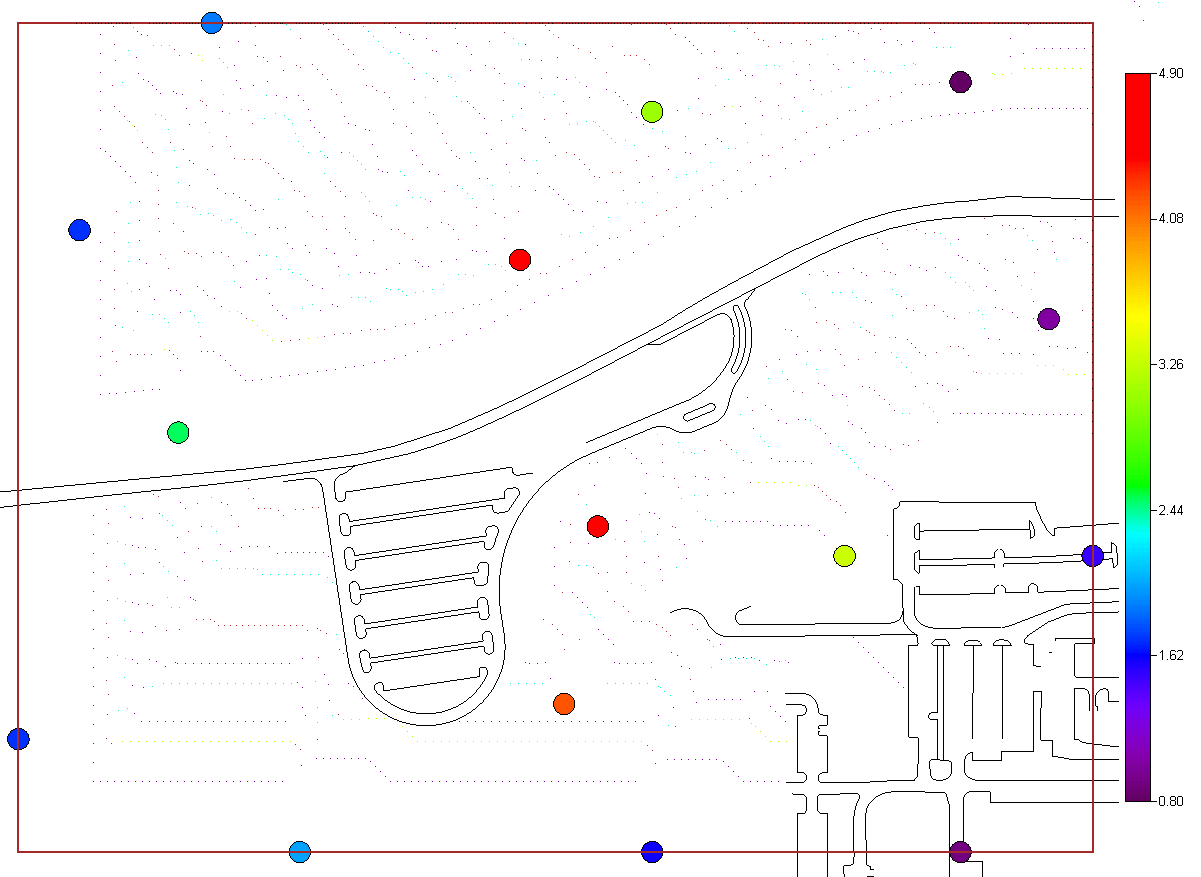
Geospatial AnalysisSeveral tools are provided in SADA for performing a geospatial analysis. These tools include methods for measuring spatial correlation among data, modeling spatial correlation, and producing concentration, risk, probability, variance, and cleanup maps. Among these tools includue seven options:
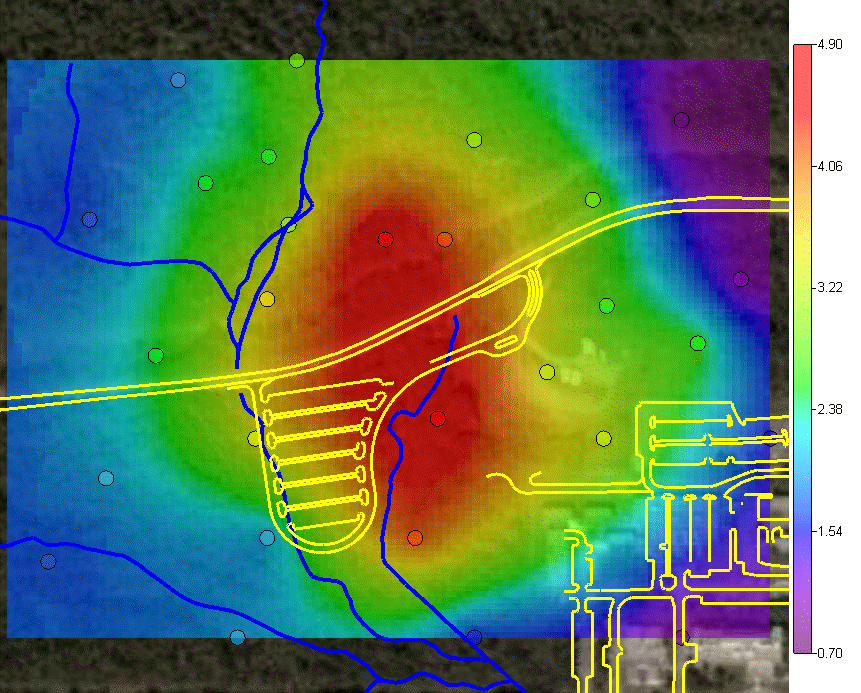
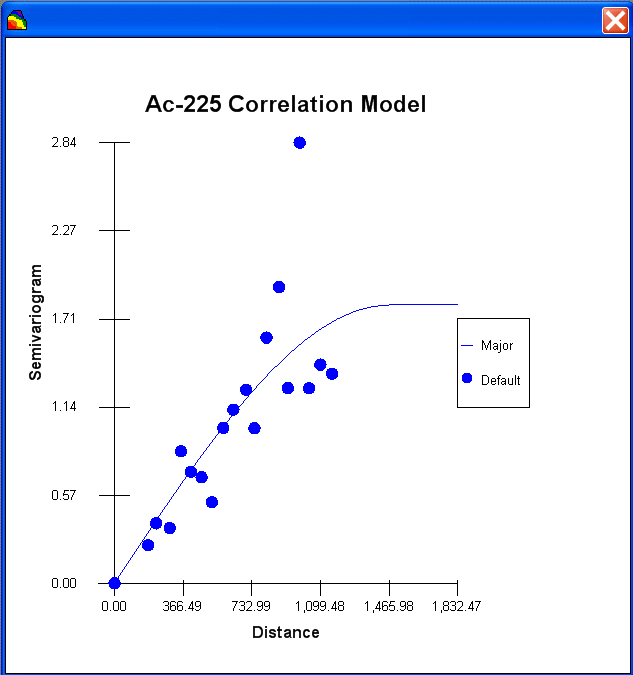
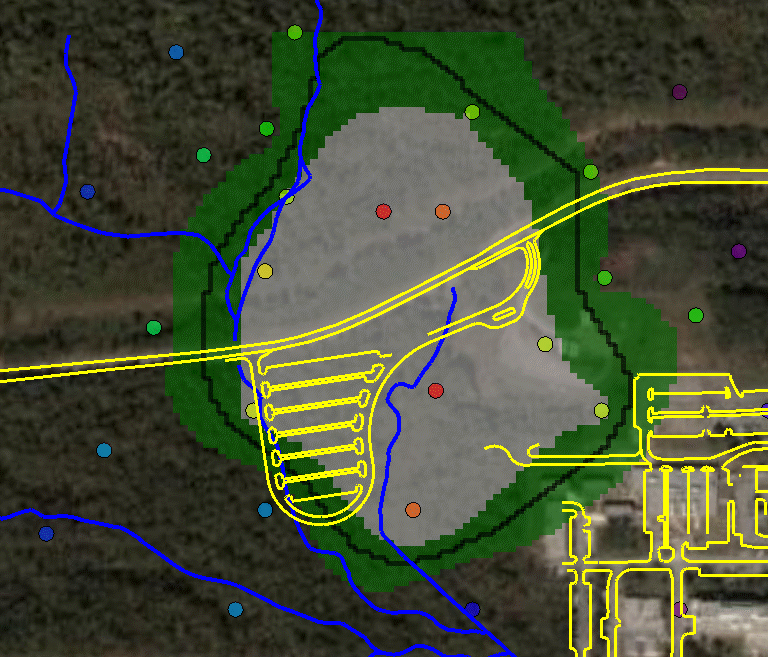
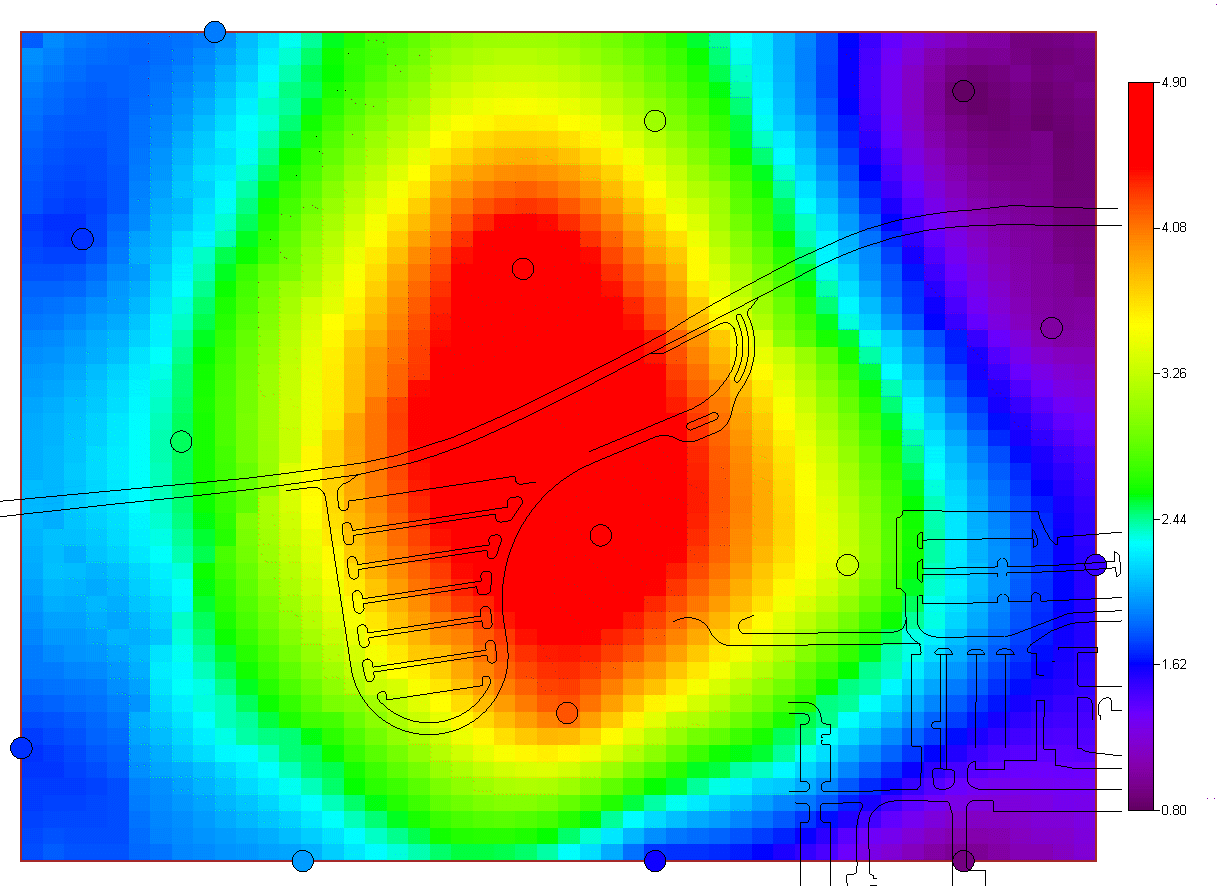
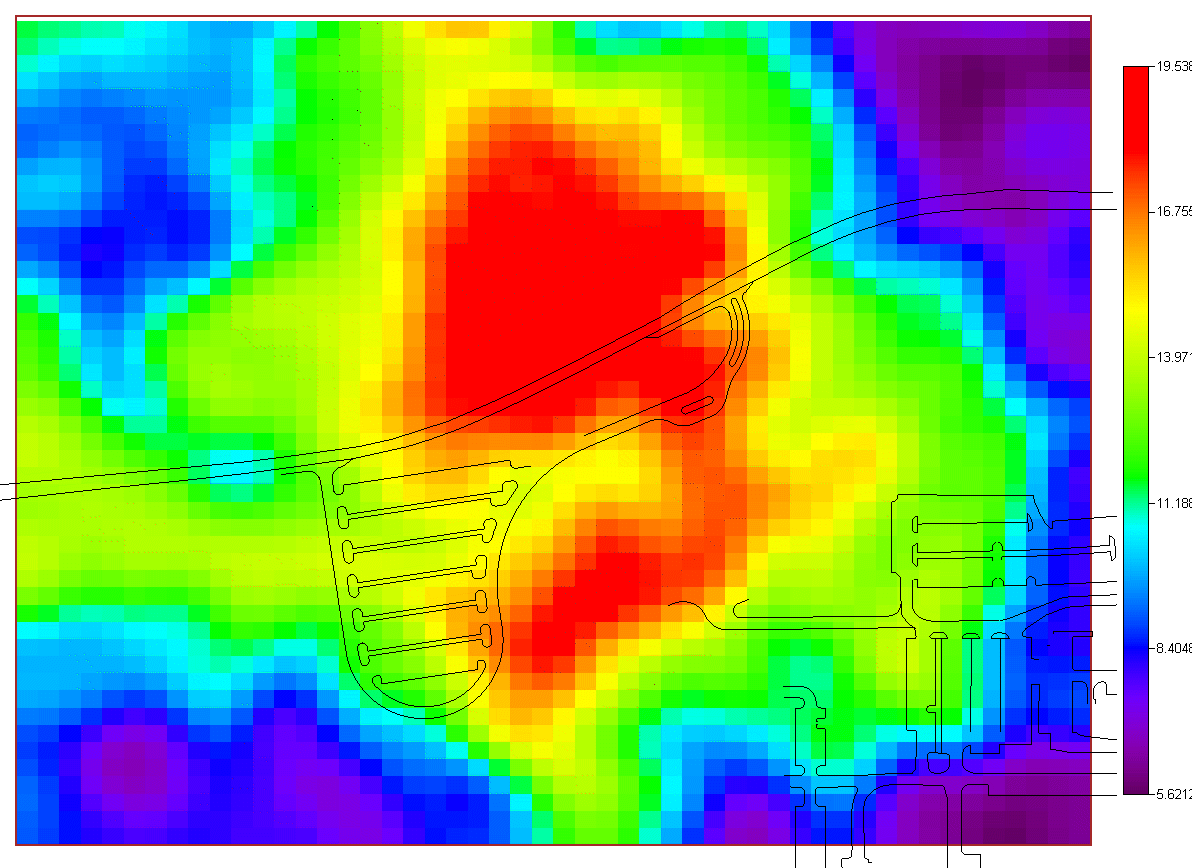
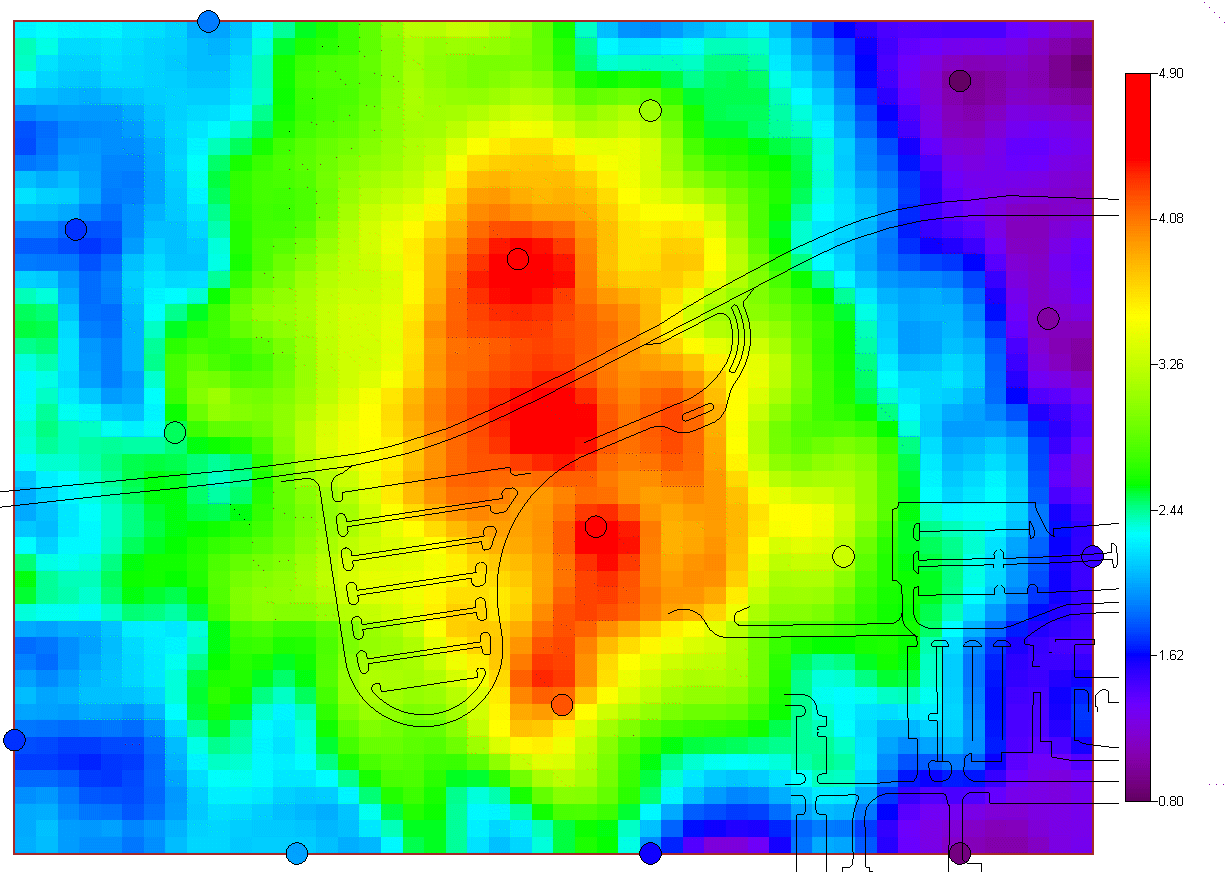
and two simulation methods. The last option "import your own" may be of particular interest. SADA has a couple of industry standard formats (ASCII Grid, FLOAT Grid) as well as a SADA format (fairly low requirements for importing 3d models) for importing your own models. When you import your own models, they can be used in line with the other modeling and decision analysis features just as if they were generated in SADA. Basic estimation methods such as inverse distance, natural neighbor, and nearest neighbor produce a single estimation map for a given set of model parameters. Natural neighbor is particularly easy for novice users as it requires no input from the user (based on simple geometries). Kriging goes beyond estimation to provide a model of uncertainty that is useful in determining how well understood estimation values are. Often kriging results are very smoothed. This can be aleviated by the use of heterogenous secondary data (see below) to better inform the kriging model about local variations. In addition, simulation models provide full access to point and joint uncertainty assessments and also produce more heterogeous maps the attribute (contaminant) of interest.The following shows some typical applications of SADA geospatial models. In the first image we see an evaluation of correlation structure by creating a variogram map (rose) in search of anisotropic conditions and then the fitting of a model through experimental variogram results. The user has some assistance in this often challenging aspect of a geostatistical analysis with recommendations, autofitting, etc.
In many situations, there is insufficient data to reasonably build a geospatial model of any kind. Maps of these types of geospatial models are very, very smooth.
|

SADA Main Page Free Downloads Visualization Sampling Data Exploration Risk Assessment Geospatial Analysis Geospatial Simulation Decision Analysis Cost Benefit Anaylsis MARSSIM TRIAD Other Tools Technical Support Documentation Coming Soon Training Education Applications Join SADA User Group RAIS Bugs People Email Us