
This sampling routine identifies new sample locations where concentration levels predicted by the geospatial model would result in an area of concern that is less than (minimize) or greater than (maximize) the current area of concern. The idea is simple in concept but can be computationally very intensive.
Consider SADA’s approach to other geospatially-based secondary sample designs, such as the high value design. If K new samples are requested and the user chooses to perform a simulated sample design, then SADA will initially contour the area and explore all nodes to identify the node with the highest modeled value. The location of this node then becomes a new sample location. The site is then re-contoured using the predicted value at the node as if it were a real sample point. The site is then re-explored to find the next highest predicted value. So for K new samples, the site is re-contoured K times. The total number of block estimations, N, would estimated as
N = K x (B-1) - 1
Where B is the number of blocks to be estimated in the volume. So, for a trivial three-dimensional application of 4x4 blocks and 2 layers (32 blocks), a site would be contoured 10 times to get 10 new samples or 309 blocks. Typically, applications of 100x100 with 5 layers take a few seconds to a couple of minutes to complete on most computers.
Note that this is an estimation, since some actual samples could inadvertently exist at a node value, reducing the number of blocks to estimate. This rarely occurs in practice. N can be a large number and require some time for large values of B.
This approach is not feasible for determining which sample node would reduce or increase the area of concern. A simple exploration of node values will not identify which node produces a reduction/increase in the area of concern. Rather for each new sample, the site would have to be re-contoured for each node using that node’s value as a simulated sample value. SADA would then choose the node that result in the smallest or greatest area of concern as a sample. This results in unacceptably high computational time. In particular, the number of calculations would be estimated as
N = B! – (B-K)!
Consider a trivial three-dimensional scheme with 4x4 blocks and 2 layers (32 blocks). To identify 2 new samples, minimizing or maximizing the area of concern would require the site to be re-contoured N = 32! – (32-2)! = 32!-30! = 2.62E+35. It is fairly common to see 100x100 blocks with 5 or more layers (B=50,000).
The location of a new sample will have a certain impact on the area of concern. In general, because of the nature of most spatial models, particularly those found in SADA, small changes in the location of that sample will have little or no practical impact on the area of concern. Therefore, from a practical standpoint, there is little need in investigating every single node, particularly for dense grids. It would be more computationally practical to select a subset of nodes to investigate. As illustrated above, however, even investigating a subset of 32 nodes is impractical.
Simulation of sampling designs is a useful approach for this overwhelming situation. Rather than visiting a subset of nodes one at a time, SADA randomly selects K nodes at a time from the full grid and calculates their impact on the area of concern. This represents one simulation of the design. If this process is repeated P times, the number of blocks estimated will be
N = P(B-K)
So, choosing 10 new samples from a 100x100 by 5 layer design by simulating the design 100 times will result in 100 site contours or N = 100(50000-10) = 4999000 blocks. This takes only 2-3 minutes on a typical P4 machine with 490 sampled data points.
However, random selection across the entire site is an ineffective method for locating new samples. The presence of spatial correlation is an important theme in spatial mapping and in most cases, the closer sample points to a region of interest the more impact they have on the final result. It stands to reason that under most practical scenarios, those sample points that are in close proximity to the area of concern (but not contained within) are more highly correlated with and have a larger impact on regions found in the nearby area of concern than those located much further away.
Defining "nearby the area of concern" in any generalized way is difficult at best, given spatial correlation structures and the spatial arrangement of sampled points. This could be achieved through observed correlation lengths or search neighborhood parameters, but such guidelines are not universal (e.g. natural neighbor) to all contouring tools.
Still, it is important to recognize this spatial relationship and make use of it during simulation. As a result, SADA adheres to the following numerical approach for finding the greatest reduction or increase in the area of concern. For simplicity, we concentrate on minimization of the area of concern.
Given an area of concern map, SADA identifies 5 spatial bands around the area of concern called near field neighborhoods. In the figure below, the gray area is the area of concern and the blue areas are the neighborhood bands.
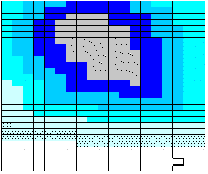
The requested number of simulations is divided evenly by 5. SADA then simulates the sample designs in increasing neighborhoods. For example, if the user requests 500 simulations, the first 100 simulations are constrained to the first neighborhood.
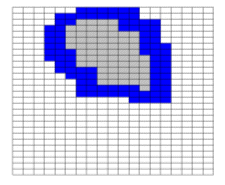
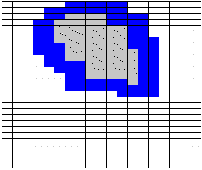
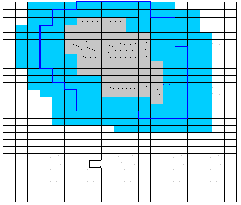
The second 100 simulations are constrained to the first and second neighborhood.
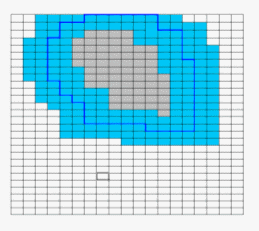
The same is true for the other simulations. This approach forces a preferential simulation in those areas near the area of concern. This is repeated for all five neighborhoods. The winning sample design from each neighborhood is compared, and the sample design with the greatest impact on the area of concern is selected as the winning sample design.
Of course when nodes are evaluated as potential sample point candidates, the normal constraints (such as separate by minimum distance) apply if the users requests.
During testing, this approach has proven to yield greater impact designs than when the entire site is permitted for all simulations. Typically, the first or second neighborhood will contain the winning design with the 4rd through 5th rarely yielding the better result.
The bandwidths are estimated to be 1/10 the distance across the farthest horizontal extent of the site. So, a site that is 50 nodes by 100 nodes will have a neighborhood bandwidth of 10 nodes. Utilizing 5 neighborhoods will cover at least half the distance across the site and should be more than sufficient to identify optimal designs. Under rare conditions, it may be that SADA cannot identify any valid sample point nodes within these neighborhoods due to the minimum distance constraint. Under these situations, the neighborhoods are expanded to include the entire width of the site.
SADA reports the winning design as well as the expected increase or decrease in size of the area of concern. It is recommended that the user use at least 500 simulations. This would produce 100 simulations per neighborhood. More than 500 is preferred when possible. The greater the number of simulations, the more optimal the search design will be.
The principles of maximization work conversely. Neighborhood bands are found inside the area of concern and the winning design creates the greatest increase in the area of concern.
Coring issues
When SADA is identifying a set of K samples under the "minimize the area of concern" framework, it only searches through nodes that are currently considered "clean". Therefore, SADA will never choose a point inside the area of concern to attempt to minimize the area of concern. This would result in the placement of a sample in the design greater than the design criteria and could expand the area of concern.
However, during coring in a 3d application, a winning design may include a new sample point located underneath an area of concern. In fact, SADA is trying to bound or minimize the AOC from underneath. When this occurs with the coring option selected, SADA will also include all samples in the core (some of which may be included in the area of concern). This can reduce the impact of the non-AOC sample point located beneath the AOC but attempts to reflect the true impact of analyzing cores rather than single points. For this reason, using the core option in 3d can sometimes yield smaller impacts to the area of concern because of this very situation. Turning off coring can greatly increase the impact to the area of concern because no simulated sample points will ever be greater than the decision criteria. While this may have a desirable affect on the area of concern, it may not reflect the reality of true soil coring activities. Furthermore, it assumes that other information found elsewhere in the core will be ignored, particularly if it is suspected of being too high. It is recommended to adhere to the coring principle particularly in this sample design.